18 Dec 2015
I've been playing with Theano lately, implementing various neural networks and other computations to see if they are suitable to Theano's programming model.
Wikipedia says:
Theano is a numerical computation library for Python.
I find this misleading - a better description is that Theano is a mathematical expression compiler that doesn't have its own syntax but is hosted in Python instead. This has the interesting consequence that the type of abstractions that works best with Theano is not functions or objects/classes, but macros - you write functions or methods in Python that generate and compose Theano expressions. I'll explain this in more detail in this post. Interestingly, Google's TensorFlow implements the same model, so the thesis of this post should apply to TensorFlow as well.
With Theano the programmer builds a "computational graph" out of symbolic variables like this:
import theano.tensor as T
x = T.iscalar()
y = T.iscalar()
s = x+y
print s.eval({x:2, y:2}) #4
print s.eval({x:1, y:3}) #4
print (2*s).eval({x:2, y:3}) #10
Note that the value of s is an expression that can be evaluated many times with different input values, and as part of different computations. It essentially holds a directed acyclic graph with nodes being the variables and operations/intermediate results, and vertices connecting the arguments to the operations. This graph is then optimized and executed, typically on a GPU - when the data are not scalar values but large vectors, matrices or more generally tensors, the computation can be parallelized yielding 10-20x improvement in compute time versus a CPU.
For a simple computation you write the math expressions directly in Python as above. The practical problem with that is that very soon you find yourself writing similar expressions with minor differences over and over. The code quickly becomes unwieldy - it is as if you are trying to program without functions or objects! There is lots of Theano code like this on GitHub.
An example of repeated code is the code you use to optimize a cost function with gradient descent. You have to specify how to update parameters on every iteration - here is an example with 2 parameters:
lr = 0.1 # learning rate; how much to move the parameters in the direction of the gradient
# theano will warn you that the order of updates is undefined since we use a dict, but the order doesn't matter
updates = {
W: W-lr*T.grad(cost, W),
b: b-lr*T.grad(cost, b)
}
train_model = theano.function([x, y], outputs=cost, updates=updates)
Note that the learning rate lr is a Python variable, not a Theano symbolic variable, so it's a constant at the Theano graph compile time (the last line is when compilation happens).
This seems simple enough, but you may have many parameters, and add / remove them many times experimenting, so how could you remove the repetition? How about writing a function that produces all the necessary updates for a list of your model's parameters, used like this:
train_model = theano.function([x, y], outputs=cost, updates=sgd(0.1, cost, W, b))
Here is an implementation with a dict comprehension:
def sgd(lr, cost, *vs):
return {v: v-lr*T.grad(cost, v) for v in vs}
Another example is regularization - L2 regularization takes the weight matrices that parametrize your model, and includes the sum of squared values of the weights in the cost function, like this:
# logistic regression has only one matrix W, but a 2-layer network would have 2 weight matrices W0 and W1
cost = loss + 0.01*((W0**2).sum() +(W1**2).sum())
We could generate that term:
def L2(l, *vs):
return l*T.add(*((v**2).sum() for v in vs))
cost = loss + L2(0.01, W0, W1)
If you went through Theano's deep learning tutorials, you have probably realized that the classes implementing logistic regression, hidden layers, etc. have methods doing exactly that - they generate pieces of the computational graph that are composed together to produce the complete model.
Since Theano's computational graph contains all the information about its inputs (it's a data structure similar to a compiler's internal representation of a program, but a structure we can traverse), we could find out our parameters dynamically from the cost expression itself, without specifying it explicitly. Here is a function that finds out the variables of specific type (usually theano.tensor.SharedVariable, which is the type of vars Theano keeps state in) that your expression depends on:
def find_vars(exp, var_type=T.sharedvar.SharedVariable):
assert hasattr(exp, 'owner'), "exp must be a Theano expression"
if exp.owner:
return list(set(v for inp in exp.owner.inputs for v in find_vars(inp, var_type)))
else:
return [exp] if isinstance(exp, var_type) else []
find_vars(g, T.TensorVariable) # [<TensorType(int32, scalar)>, <TensorType(int32, scalar)>] x and y
This means we could minimize a cost function using gradient descent like this:
def minimize_cost(inputs, cost, lr): # simplified, should accept all params of theano.function(...)
return theano.function(inputs, cost, updates=sgd(lr, cost, *find_vars(cost)))
Adding regularization is left as an exercise for the reader (hint: usually only the weight matrices are included in the regularization term, not the bias vectors).
Thanks to Stefan Petrov for suggestions and corrections.
23 Dec 2014
(and What To Do About It)
Cost at scale
Software is famous for having marginal cost of essentially zero (the marginal cost is the cost of producing one more unit after the up-front cost, like building a factory, has been paid). This has big implications:
- a natural winner-take-all dynamics of markets
- venture capital ecosystem works
- open source is economically possible
Note: If you believe software is eating the world, this has interesting implications about the way the world of atoms is going to change soon. With software becoming a bigger component of physical goods and services, the fixed cost component to them is going to increase and the marginal cost is going to decrease. This means we might start to see some of the software-world dynamics (winner-take-all, venture capital, maybe even open source) in the physical economics as well. Uber and Tesla may be just precursors to a larger trend.
UI
Unlike the rest of the software, user interface has substantial marginal cost. An interface has two sides, UI has a software and a human side, each having different cost characteristics:
- The software side has large fixed cost to build, and zero marginal cost.
- The human side is the cost to adapt your users' brains to the way the software side of your UI works. The up-front cost here is e.g. the cost of creating the user manual, the marginal cost is training, support, or hidden in the smaller viral coefficient of your consumer app.
This understanding allows you to make decisions if and when to invest more in the software side of good UI, in order to reduce the marginal cost on the human side. It also means having a minimal UI is a good thing all else being equal.
Modeling a domain
Typical software models a part of the world with a set of hard rules. The user manipulates this formal model directly applying these rules via the user interface. Secondary effects from user actions are inferred by software and reflected in the model.
For example, in word processing, you get to manipulate text at higher level (type and edit text, apply formatting), with software inferring low level details (line breaks at page width, text flow around images, repeating header/footer etc). The computer maintains a model of text and applies deterministic operations on it. The model is fully transparent to the user, in fact he needs to understand it in order to use the software. After almost 40 years evolution and integration in the mainstream writing culture, the basic operations (typing and editing, line breaks, bold/italic/font/size formatting) feel natural. More complex things like maintaining consistent styling in a document are harder.
How to make minimal UI
One way to make UI (or software) more useful is to have a richer formal model that infers and silently does many useful things: like a spreadsheet does formula recalculation, or like databases utilize indices and nontrivial plan optimizations to execute queries. Unfortunately, good formal models are few and far between.
When a nice formal theory of the domain is not available, you can still fake it by inferring side effects with a predictive model, or machine learning. For example, a word processing program might try to infer what is the consistent styling that the user wants and apply it. A good UI might be one that hides part of the internally used model and asks the user to provide only examples of what he wants done. If the inference is good enough, that simplifies the user's mental model, so it reduces the marginal cost of your software.
24 Jul 2014
Monkey patching is universally considered a bad practice. Many people avoid having anything to do with it (and with projects that use it, like gevent), without considering if the actual reasons for avoiding it apply to their case. So what are these reasons? I think the important ones are:
The patched code works very differently from the unpatched, breaking assumptions the rest of the code has about it.
Monkey patches making assumptions about the code they patch that are implementation detail and change between versions
(Aside: Most nontrivial errors are about programmer coding wrong assumptions. These can be low level assumptions about how the code behaves or higher level assumptions about the domain that is being modeled.)
Monkey patching is too general so it's easy to slip into one of these. Note that the same applies about things like inheritance (vs composition). You can avoid these problems with monkey patching if you:
Write code to monkey patch functions or methods as decorators. Make that decorator general, i.e. assume as little about the modified code as possible.
It is the second sentence that takes care of the problems above, but it is the decorators that make it possible to write such code (this is not strictly true, any higher order function will do, but decorators provide a nice convention with syntax sugar as an added bonus). We can apply Python decorators on existing functions and methods to permanently modify their behavior. Let's see how it's done concretely.
Decorators
If you haven't actually created decorators, you may think about them as magic syntax sugar and not realize what decorators are actually designed to do is to be functions that take another function as an argument and modify it's behavior. However, decorators are usually applied at the moment of defining the function they apply to, this is when their special syntax is designed to be used:
@decorator
def func(arg1, arg2):
pass
Without the syntax sugar, the way to do the same would be (note you can do this also in e.g. Javascript, so this style of monkey patching is available to you in other dynamic languages besides Python):
def func(arg1, arg2):
pass
func = decorator(func)
If the last line is separate from the function declaration, and the function wasn't specifically written to be decorated, you will effectively do monkey patching. Some decorators (e.g. doing logging) don't make any assumptions about the functions they decorate, and the decorated functions could be used without any decorator. Others (like bottlepy's routing decorators or memoize that you'll see bellow) make only a few assumptions.
If you do monkey patching with decorators, you avoid the problems with them, because decorators are written to modify the function's behavior in an orthogonal way. Let's see a specific real-world example.
High volume HTTP requests and DNS resolution
A common gotcha when writing a crawler is that the bottleneck you will likely hit first is the DNS resolution. I also hit this problem when prototyping https://t1mr.com (pronounced 'timer', a website availability tool whose basic function is to make an http request to your site every minute and notify you if it's down). It is weird to diagnose because, depending on your DNS infrastructure, you can get various failures:
- your home / office router may crash
- the DNS infrastructure of your hosting provider may start to return random errors for some of the requests - some timeouts, some other failures (I experienced this with both Hetzner and Amazon EC2)
- Google's Public DNS service would actually behave quite nicely by servicing all your requests, although rate limiting them to 10 resolutions per second.
I eventually settled to use Google's DNS because it's solid and predictable. But I wanted to make the basic service for t1mr free, so it had to be cheap to run and scale well on a single machine. 10 req/second are just 600 per minute, and I really wanted to saturate the network link.
Normally one would set up a DNS cache on his server and use that. I didn't quite get this to work (perhaps I exhausted the cache), but I didn't really try because I wanted maximum control over when and how the domain names are resolved. So how can you implement such a cache in the application?
DNS resolutions are normally handled by the OS. When you open a socket to a remote server specified by name, the OS blocks that system call and resolves it (unless it is already cached). Resolution can take 100s of milliseconds, that's why high level frameworks that allow non-blocking code (Python with gevent or node.js) has their own way of doing it (they both use c-ares or blocking OS syscalls in threadpools depending on configuration).
You can modify the http call to use an IP address and set the Host header appropriately. This works, although you have to do it yourself because http libraries typically lack support for it. But in t1mr.com I want to provide checking other types of services besides http, say ICMP ping or SMTP check. The other protocols lack the option to use an IP and specify the domain name separately.
What I did instead was monkey-patch getaddrinfo(the function that resolves domain names) with a memoization decorator. Here is a generic memoizer:
def memoize(f):
global cache
cache= {}
def memf(*x):
if x not in cache:
cache[x] = f(*x)
return cache[x]
return memf
It is very general and can be used with pretty much any function, like:
@memoize
def fib(n):
if n<2:
return 1
else:
return fib(n-1)+fib(n-2)
In our case, it is good enough for prototyping. Here is how to monkey-patch socket.getaddrinfo with it:
import socket
socket.getaddrinfo = memoize(socket.getaddrinfo)
In production we use gevent for efficient networking and a different decorator (that behaves mostly like a cache with expiration). Any networking code will now use under the hood our modified getaddrinfo, resolve the domain name only the first time and use a cached value from now on (until the memoizer decides it is time to refresh).
This might seem like an isolated example where it's a good idea to patch lower level function, but it's not.
Layered abstractions
Basically all computing is built on layers upon layers of abstractions. It is considered a good idea to implement a layer relying only upon the layer bellow, and it is. Networks are probably the canonical example. One of the actual limits of this model is that you have to expose the low level abstractions to the high level for tweaking. If you don't have a mechanism to do this, low level abstractions often leak in a way that is not fixable from the high level code. Monkey patching the lower levels is not a panacea, but it can help here.
Conclusion
Monkey patching is seen as an ugly kludge, but is still used quite a lot because people lack better ways to accomplish their goals using the abstractions available in their language. One way to do safe and useful monkey patching is to write the monkey patch as a decorator, making very few assumptions about the function being decorated, and get a nice orthogonal abstraction in this way.
22 May 2014
In this post I will explore the possibility to write CRUD web applications without using a relational or nosql database - have the data tier collapse into the application. I'll show that within certain constraints it is a fast and fun thing to do, very similar to building a prototype, but one that exhibits the characteristics of production-quality software. The resulting architecture is somewhat similar to Redis, except that it would be a (tiny) library instead of a separate server.
The basic idea is simple: have a single process single threaded application. Use a high level language supporting green threads with async I/O (cooperative multitasking within the application) to make it responsive and appear doing multiple things at once, but without the difficulties of real multithreaded programming (no locks or mutexes necessary). Implement simple on-disk persistence.
Let's see what all this means and how the various pieces of this puzzle fall into places. There are certain assumptions that seem disturbing but can be relaxed with a bit more software infrastructure - notably that the data must fit into memory when represented in the language's natural data structures. I will use Python, although other stacks can be used with similar effect, notably node.js.
People use databases for query/indexing functionality, persistence and easy concurrent code. Let's look how we would handle all these.
Data model, indexing and queries
As we'll keep everything in memory, we'll just use the language facilities to organize data, modify and query them. This could be a big topic, but I won't go into much details here. A good way to start would be a structure of nested lists and dicts/hashes that starts from a root variable and can be traversed using normal language syntax. Queries are easily expressed in Python with list comprehensions. Here is an example structure for a web app with registered users, containing mostly login info:
At login attempts you would look up the user's email address directly in the root, and generally you should structure your data in such a way that you don't need to iterate in order to find a piece of data. The data structures available in the standard library may not be enough, for example you might need to use something like blist for ordered collections with fast lookup. You might also want to use dedicated classes instead of generic dicts for your objects (using them with _slots_ would also reduce memory usage).
A query showing the percentage of users who opted in for your newsletter would look like:
sum(u['options']['newsletter'] for u in root.values()) / float(len(root))
Easy concurrent code - Atomic, Isolated and Consistent
Typical web applications are written so that the only shared state resides in the database. It takes care of concurrent access to the shared state - which is what the first three letters from ACID are about. We will keep all data in memory and use event driven architecture (single process, single thread) instead.
In Python I do it with gevent. Gevent lets you write code that does asynchronous network I/O. Node.js is similar, but it uses callbacks while gevent uses coroutines. Many people don't realize that the code they write with gevent or node.js has very different concurrency properties than the code that uses normal threads. When you use normal threads, you are exposed to race conditions everywhere in your code except where you use explicit concurrency primitives to avoid it. When you use gevent or node.js, there is a single process, so a single address space holding all of your data, and a single thread modifying them. Whenever you do I/O, the context switches to a different green thread (gevent) or different callback (node.js), creating the illusion of parallel execution. But now we can have race conditions only on the I/O boundaries, where execution switches. As long as we don't have I/O, the code executes as an atomic unit and no one interrupts it.
An example: counter
To make this concrete, consider the example of a global counter implemented with the bottle framework in Python:
#!/usr/bin/python
import gevent
from gevent import monkey;monkey.patch_all()
# hold all global state here
root=dict(cnt=0)
from bottle import route, run
@route('/')
def inc():
n = root['cnt']
# gevent.sleep is a yield statement, it switches to a different greenlet
# network I/O would have the same effect
# uncommenting it will result in incorrect count
#gevent.sleep()
root['cnt'] = n+1
return "Hello World #%i " % n
run(server='gevent', host='localhost', port=8080, debug=False)
Implemented in native OS threads without synchronization this would result in a race condition, and the counter will be less than the number of requests. With gevent, when you run the code as presented, you get:
nik@occam:~$ ab -n 1000 -c 10 http://localhost:8080/
[...]
Requests per second: 2555.79 [#/sec] (mean)
Then you can see there is no race condition and the counter is exact. Note that it is also fast, as data are in memory, and there is no locking nor interprocess communication.
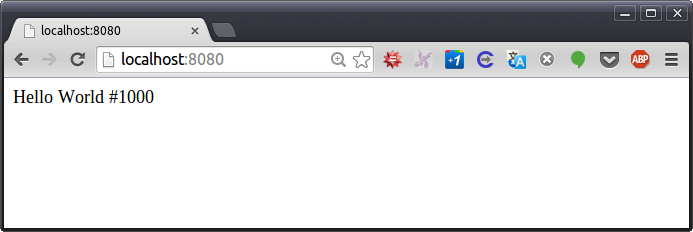
The commented gevent.sleep(0) line does a "yield", meaning that the current greenlet pauses and lets other greenlets run (which also happens when you do I/O). For our purposes this is the same as preemption by another thread at this point. If you uncomment it and re-run the test, sure enough, the counter would no longer be correct:
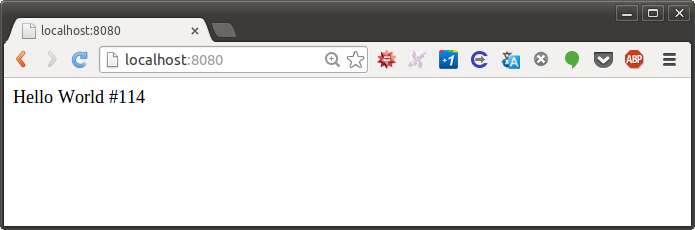
This basically means that as long as we are conscious about the I/O in our code, we can write multitasking code and reason about it fairly easily. In fact, a CRUD application that doesn't call external services, would have each HTTP request executed in one piece, with no internal I/O boundaries.
With node.js the I/O boundaries are clearly delineated by callbacks. Everything within a function executes atomically. In gevent the I/O boundaries that matter are just network I/O (disk I/O is blocking in gevent, so it doesn't cause switching to a different greenlet).
ACI
Let's ensure we cover the first 3 of the ACID database properties for code between two I/Os:
Atomicity - all code executes or nothing does. In fact, the system may crash in the middle of our code executing, but this cannot be observed from the client (web browser). If we call external services from our code, they could observe non-atomic behavior.
Consistency - we only transition between valid states. As long as the system is in valid state at the I/O calls, this property would hold. For a simple CRUD with no external services this means the programmer must make sure it is in valid state at the end of each HTTP request, which should be the case anyway. If our application only reads data from an external service, it should do so in transient variables before starting to modify its state.
Isolation - the transactions appear to be executed serially, because they are in fact executed serially.
Before I handle durability in the next section, I want to point out that a nice use case for the technique as presented so far would be implementing a multiplayer poker game - there is plenty of shared server side state, it's all transient (for the duration of the game), but concurrent updates to the state become easy. It is important not to do too much computation in one chunk as this would increase latency in handling other requests that have come during this time.
Durability
Real durability would make sure application state is fully persisted on disk before returning from an HTTP handler. We'll do this in a later post, and for now I'll show how to persist everything every minute or so without breaking the nice properties we have established already. We can call this eventual durability by analogy with eventual consistency :)
Let's dump a JSON image of the state on disk. In order to produce consistent image, we need to serialize it at once, with no I/O boundary in the middle, and this is the slowest part of the process. Actual writing of the file is an I/O boundary in node.js and synchronous operation with gevent. Here is a simple example that saves the state every minute (you can add this to the counting example above):
import tempfile, json, os
def saveSnapshot(root):
def doSave():
with tempfile.NamedTemporaryFile(delete=False) as fw:
tempname = fw.name
json.dump(root, fw)
# had to add the following 2 lines to avoid data loss
fw.flush() # flush any userspace buffers
# fsync would block the process
# so run os.fsync(fw.fileno()) in a thread pool
gevent.get_hub().threadpool.apply(os.fsync, (fw.fileno(),))
# note os.fsync is native and doesn't engage GIL,
# allowing other code to run
os.rename(tempname, 'snapshot.json')
try:
while True:
gevent.sleep(60)
doSave()
except gevent.GreenletExit:
doSave()
gevent.spawn(saveSnapshot, root)
Note that it doesn't fsync (guarantee it's written to disk when the code completes). The write system call returns as soon as the data are in OS's buffers, so it would be fast. The precise moment the data hit the disk doesn't matter because the previous snapshot would be available. Data integrity should also be OK because the file system is supposed to take care and do the rename only after it has fully written the file. Nevertheless I'll provide an fsyncing implementation in a follow up.
Turned out the OS (at least Ubuntu 12.04 with ext4) doesn't guarantee renaming would happen after the file is written to disk. In fact, it would happily rename the file before committing new snapshot to disk, thus losing the old snapshot. Power loss in this moment leaves you with truncated, unusable snapshot. So I fsync the file here, in gevent's default threadpool so that I don't block the main thread from serving requests while it is fsyncing. I don't fsync the rename operation, but it's guaranteed rename will happen after writing the snapshot to disk.
Scalability bottlenecks
Here are the bottlenecks you are likely to encounter as you scale the application. I'll provide guidelines and fixes for them in follow up posts:
- Snapshot becomes too big to serialize at once
- Snapshot becomes too big to fsync to disk at once
- State doesn't fit in RAM
- A single core can't handle all processing
An initial implementation using this architecture should be about as expensive as a throwaway prototype, so don't be afraid to start with it. When you need scale you can rewrite it using anything else with the benefit that you will know more about both your users' problem and how its technical solution should be implemented.
Redis comparison
Redis is built using very similar principles internally: it is single threaded so no complex locking or synchronization is necessary. We have also implemented one of the Redis persistence mechanisms: RDB snapshotting. Redis does the snapshotting somewhat differently: it forks the database process and the parent continues serving requests while the child serializes the data. The memory after fork() is separate, so the new request won't affect the snapshot in progress. We could do this in Python too (node.js lacks real fork) and avoid blocking the http server while serializing. However, this mechanism works better for Redis than it would in a high level language library. This is because Linux implements the logical separation of memory after fork() using copy-on-write, so the memory pages are actually shared between the parent and the child until the parent (that continues serving database requests) modifies some of them (at which point the OS produces a separate copy of the modified pages).
This works well in C, but in Python the OS would actually copy the memory of the parent process immediately. This costs CPU and uses twice the memory on snapshotting. Why would the memory split? Because of the automatic memory management in Python, which uses reference counters and stores them with the memory objects. While you traverse the object graph in order to serialize it, you would modify these reference counters and the OS would copy all the memory. This behavior is not unique to Python, the automatic memory management of other high level languages like Ruby interferes with the virtual memory copy-on-write mechanism in a similar way.
What is the difference between writing a Python app using DIY NoSql and a Python app using a Redis back-end? With Redis the data have to cross inter-process boundary to move between the application process and the database process. In fact, they often have to do it multiple times per http request with latencies and CPU usage to serialize/deserialize data adding up. That's why Redis got Lua scripting - to be able to do application logic close to the data. Actually Redis with scripting is similar to the DIY NoSql architecture, except that now you can use languages other than Lua for scripting and the data storage mechanisms are embedded in the language vs the language being embedded in the data storage mechanisms.
Use cases
There are a couple of public apps running on this architecture.
t1mr.com
t1mr.com is a service that pings your site every minute to verify it is running (and might try to restart it if it's down and your hosting provider has the API). I wanted the basic functionality to be free so it had to be very efficient. It cycles all the sites every minute, so an in-memory database is a good fit for it. It is network bound and can monitor tens of thousands of sites using a single core.
fleetnavi.com
fleetnavi.com is a service that optimizes delivery routes. It solves a vehicle routing problem (a generalization of traveling salesman problem with multiple vehicles, time, capacity and other constraints) using Google Maps data. There are no particular performance constraints requiring the DIY NoSql, but it was the simplest and most flexible option. The optimization solvers run in external processes, so they don't block the web server.
29 Apr 2014
A lot of the troubles in software development I've seen stem from putting too much structure in your code. Too many layers of indirection, too much meta, too many classes, too much inheritance, too many FactoryFactories. In a series of posts I'll attempt to show a different way: building small, orthogonal (arbitrary composable) abstractions and using them to do your job with minimal amount of code. The code you write with them should express your intent directly, in the problem domain, not hide it behind some incidental structure of the programming domain.
Here are some examples of beautiful code in Python that are not overengineered:
